社内のマニュアル、議事録、提案書——それらがクラウドストレージに保存されているのに、「あの資料どこだっけ?」という状況は毎週起きています。RAG(Retrieval-Augmented Generation)を使えば、クラウドストレージのファイルをAIで横断検索し、自然言語で質問するだけで答えを引き出せます。
RAGとは
RAGは「検索拡張生成」の略です。LLM(大規模言語モデル)が回答を生成するとき、外部のデータソースを参照する技術を指します。
通常のChatGPTやClaudeは事前学習データに基づいて回答します。自社固有の情報——社内規定、製品マニュアル、過去の提案書——は学習データに含まれていないため、これらについて質問しても正確な答えは返ってきません。
RAGはこの問題を解決します。質問が来たとき、まず社内データソースから関連文書を検索し、その内容を文脈としてLLMに渡します。LLMは自社資料を参照しながら回答を生成するため、「うちの会社の場合はどうか」という質問に具体的に答えられます。
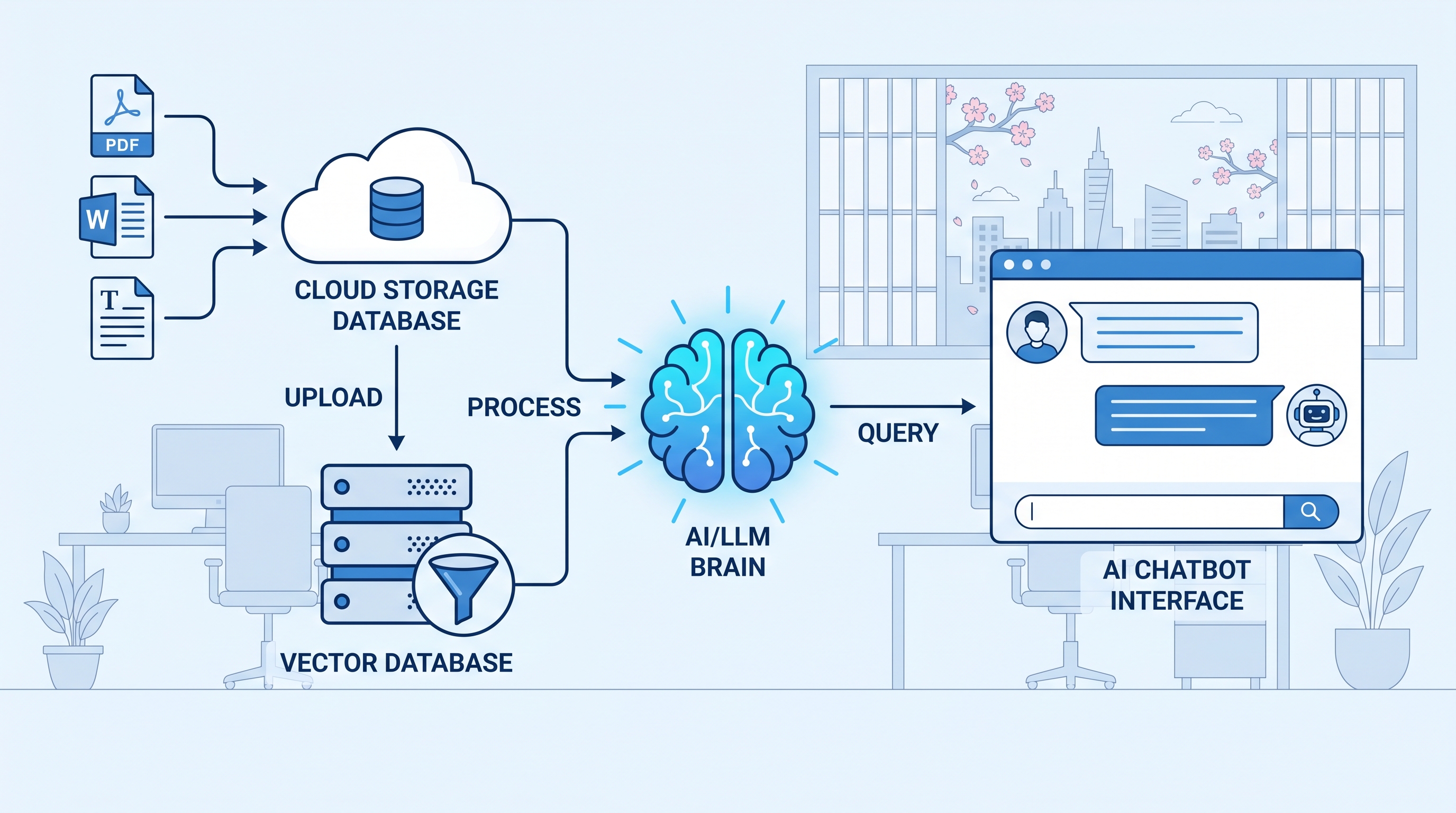
クラウドストレージとRAGの相性
RAGシステムのデータソースをどこに置くかで、運用負荷が大きく変わります。
ローカルフォルダにファイルを置く方法は手軽ですが、複数人が更新するファイルの管理や、新規追加ファイルの同期が面倒になります。クラウドストレージをデータソースにすると、この問題が解決します。
常に最新のファイルが参照される:誰かがマニュアルを更新すれば、次回のRAGインデックス作成時に自動で反映されます。手動での同期作業は不要です。
S3互換APIで接続できる:LangChainを含む多くのRAGフレームワークはS3互換APIをサポートしており、AWSのSDKがそのまま動きます。ストレージを切り替えてもコードの変更は最小限で済みます。
アクセス制御をストレージ側に集約できる:営業部のファイルはRAGで参照でき、人事部の機密書類はRAGから除外する——こういった制御がストレージ側の権限設定で実現できます。RAGシステム側に複雑な認可ロジックを持ち込む必要はありません。
LangChainを使ったS3ストレージ連携
S3互換APIを持つストレージとRAGを連携させる最も一般的な方法が、LangChainのS3DirectoryLoaderを使う方法です。AWS S3以外のS3互換ストレージでも同じコードで動きます。
from langchain_community.document_loaders import S3DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# S3互換ストレージからドキュメントを読み込む
loader = S3DirectoryLoader(
"your-bucket-name",
endpoint_url="https://your-storage-endpoint",
aws_access_key_id="YOUR_ACCESS_KEY",
aws_secret_access_key="YOUR_SECRET_KEY"
)
docs = loader.load()
# ドキュメントを分割してベクトル化
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
split_docs = splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(split_docs, embeddings)
# 質問して答えを得る
retriever = vectorstore.as_retriever()
results = retriever.invoke("有給休暇の申請方法を教えてください")
endpoint_urlにHStorageのS3互換エンドポイントを指定するだけで、社内ファイルをRAGのデータソースにできます。
HStorageのS3互換APIで構築する
HStorageはS3互換APIを提供しているため、LangChainのSDKをそのまま使えます。
接続に必要な情報は管理画面から取得できます:
- エンドポイントURL:
https://s3.hstorage.jp - アクセスキー / シークレットキー:管理画面のAPI設定で発行
- バケット名:アップロード先のフォルダ名
RAGに使うファイルは、HStorageの専用フォルダにまとめて保存します。PDF、Word、テキストファイル、Markdownなど複数のフォーマットが混在していても問題ありません。S3DirectoryLoaderがファイル形式を自動判定してロードします。
社内規定のPDFを更新したら、HStorageにアップロードするだけです。次回RAGシステムがファイルを再読み込みするときに最新版が使われます。
対応ファイル形式と前処理
RAGシステムで扱えるファイル形式は、使用するLangChainのローダーによって決まります。代表的なものは以下の通りです:
| ファイル形式 | LangChain ローダー |
|---|---|
| PyPDFLoader | |
| Word (.docx) | Docx2txtLoader |
| テキスト / Markdown | TextLoader |
| PowerPoint | UnstructuredPowerPointLoader |
| Excel | UnstructuredExcelLoader |
スキャンしたPDFや画像ファイルはテキスト抽出できないため、OCR処理が別途必要になります。テキストデータがメインの社内資料であれば、大半のファイルはそのまま読み込めます。
セキュリティ設計の基本
クラウドストレージをRAGのデータソースに使う場合、アクセス制御の設計が漏洩リスクを左右します。
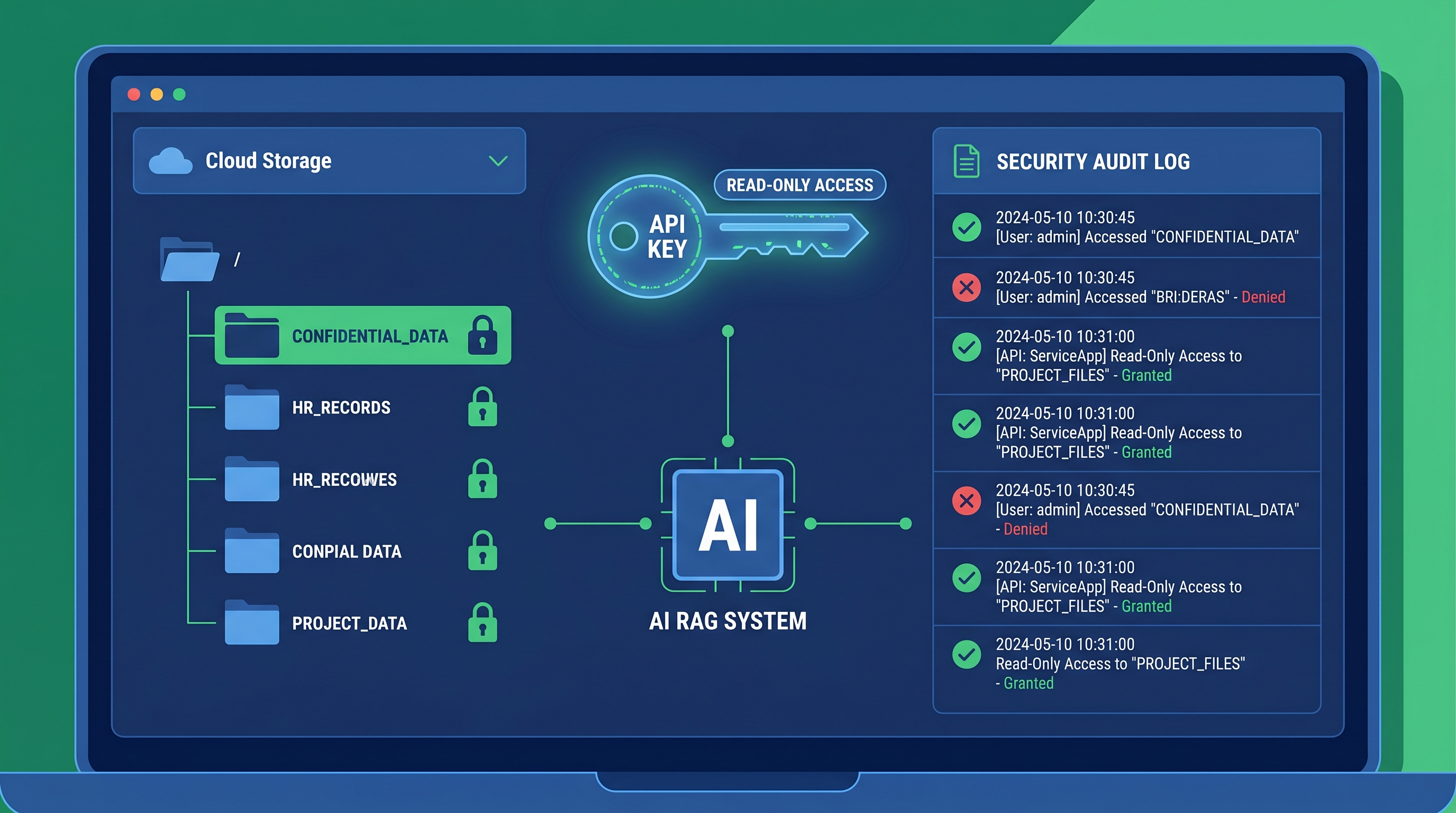
RAG専用フォルダの分離
HStorageの権限設定を使って、RAGシステムが読み取れるフォルダを「全社共有」フォルダに限定します。機密書類は別フォルダに置き、RAG用のAPIキーにはそのフォルダへのアクセス権を与えません。「全社員がアクセスするRAGに役員限定の資料が混入する」という事故を防げます。
APIキーの読み取り専用化
RAGシステム専用のAPIキーを発行し、読み取り専用の権限に限定します。書き込み権限は不要です。万一APIキーが漏洩しても、ファイルの書き換えや削除ができない状態にしておきます。
アクセスログの確認
HStorageのアクセスログで、RAGシステムがどのファイルを参照したかを確認できます。意図していないフォルダへのアクセスが発生していないか、定期的に確認する習慣をつけておきます。
実運用でのポイント
インデックスの更新頻度
RAGシステムのベクトルストアは、ファイルを更新しても自動では再構築されません。夜間バッチや定期タスクでインデックスを再構築するスケジュールを組んでおく必要があります。
更新頻度の高いファイルが多い場合は、HStorageのS3互換APIを使ってファイルアップロード後にインデックス再構築をトリガーする仕組みを作ると、常に最新の状態を維持できます。
チャンクサイズの調整
LangChainのテキストスプリッターで設定するチャンクサイズ(1チャンクのテキスト量)はRAGの精度に直接影響します。長い文書を扱う場合はchunk_size=2000程度に増やし、chunk_overlap=200を設定すると文脈の途切れを防げます。適切なサイズは文書の種類や質問の傾向によって変わるため、試行錯誤が必要です。
コストの構成
RAGシステムのコストは主に3つの要素で決まります:
- クラウドストレージの容量費用
- エンベディングのAPI費用(初回インデックス作成 + 更新時)
- LLMのAPI費用(質問1回あたり)
HStorageの場合、ストレージ費用はファイルの合計サイズに基づきます。社内文書のテキストデータは通常数GBに収まるため、ストレージ費用よりもLLMのAPI費用が主なコストになります。
クラウドストレージ選びでRAGのために確認すること
RAGのデータソースとして使うクラウドストレージを選ぶとき、2点を確認してください。
まずS3互換APIの対応範囲です。S3DirectoryLoaderはバケット内のオブジェクト一覧取得(ListObjects)とオブジェクト取得(GetObject)を使います。この2つに対応していれば動作します。
次に転送速度です。PDFや動画ファイルが大量にある場合、インデックス再構築のたびに全ファイルを再ダウンロードする構成では時間がかかります。差分だけ更新する仕組み(ETagやLastModifiedを使った変更検知)を取り入れると効率化できます。
HStorageはS3互換APIとWebDAVを提供しており、LangChainとの連携に必要な操作をすべてサポートしています。14日間の無料トライアルで実際に試してみてください。
クラウドストレージに保存した資料を「検索する」から「AIに聞く」に変えると、情報を探す時間が大幅に短縮されます。構築の技術的な障壁は高くなく、既存のクラウドストレージとLangChainを組み合わせるだけで動き始めます。