工場の温度センサー、スマートホームのカメラ、配送トラックのGPS——IoTデバイスは24時間データを生成し続けます。1台のセンサーが1分ごとにデータを送れば、1年で52万件を超えます。デバイスが100台になれば5,200万件です。このデータをどこに、どう保存するかは、IoTシステム設計の核心です。
IoTデータが抱える3つの問題
センサーデータには、一般的なファイルとは異なる特性があります。
量が膨大で止まらない:デバイスはデータを送り続けます。ストレージは書き込みが来るたびに受け付けなければならず、「後でまとめて保存」では間に合いません。
時系列で意味を持つ:温度が26.3℃というデータは単体では価値が薄い。いつ、どのデバイスで計測したかが揃って初めて使えます。保存するだけでなく、時系列で素早く取り出せる構造が必要です。
古いデータへのアクセス頻度は急落する:昨日のデータは今日も参照します。1ヶ月前のデータは分析時だけ。1年前のデータはほぼ参照しない。この特性を無視してすべてを同じコストで保存すると、ストレージ費用が際限なく増えます。
なぜS3互換ストレージがIoTに向いているのか
S3(Simple Storage Service)互換のAPIを持つオブジェクトストレージは、IoTデータの保存先として多くの現場で採用されています。
HTTPで書き込めるため、MQTTブローカーやデータパイプラインとの連携が簡単です。EMQXのようなMQTTブローカーは、ルールエンジンでメッセージを受け取り、S3互換ストレージに直接書き込む機能を標準で持っています。特別なコードを書かなくても、デバイスからクラウドストレージへのルートが完成します。
スケールが自動的に広がります。リレーショナルDBはディスクの拡張やシャーディングが必要ですが、オブジェクトストレージは容量の上限を気にせず書き込めます。デバイスが10台から1,000台に増えても、ストレージ側の設定変更は不要です。
コストが使った分だけです。デバイス台数に関係なく、実際に保存したデータ量に応じた課金になります。初期費用ゼロで始められ、データ量の増加に比例してコストが伸びます。
フォルダ設計:後で後悔しないパス設計
オブジェクトストレージにはフォルダという概念は厳密には存在しませんが、オブジェクトキー(パス)の設計がデータ取得の効率を左右します。
悪い例:
raw/sensor_data_20260612_143022.json
raw/sensor_data_20260612_143023.json
デバイスIDも種別もパスに含まれていないため、特定のデバイスのデータだけを取り出そうとすると全件スキャンが必要になります。
良い例:
iot/factory-a/temperature/2026/06/12/device-001/1749700200.json
iot/factory-a/temperature/2026/06/12/device-002/1749700200.json
iot/factory-a/humidity/2026/06/12/device-001/1749700200.json
このパス設計なら、iot/factory-a/temperature/2026/06/12/device-001/ というプレフィックスで、特定の拠点・センサー種別・日付・デバイスの組み合わせを効率的に絞り込めます。タイムスタンプはUNIXタイム(秒)にすると、言語やロケールに依存せず扱えます。
推奨するパス構造:
{サービス名}/{拠点}/{センサー種別}/{年}/{月}/{日}/{デバイスID}/{タイムスタンプ}.{拡張子}
拡張子はJSONが汎用的ですが、大量データを分析にかけるならParquet形式にするとクエリ速度が大幅に改善します。
MQTTブローカーとの連携パターン
工場や施設のIoTシステムでは、デバイスがMQTTプロトコルでデータを送るケースが多数あります。MQTTブローカー(EMQXやMosquittoなど)がメッセージを受け取り、S3互換ストレージへ転送する構成が一般的です。
EMQXを使う場合、ルールエンジンの設定でトピックパターンとS3の書き込み先を定義します:
SELECT
clientid AS device_id,
payload.temperature AS temperature,
payload.humidity AS humidity,
timestamp AS ts
FROM
"factory/#"
このルールが発火すると、EMQXはS3 SinkがJSON LinesまたはParquet形式でデータをバッチ書き込みします。1メッセージ1ファイルではなく、一定時間または一定件数でまとめて書き込む設定にすると、小さなファイルが大量に生まれる「スモールファイル問題」を防げます。
Pythonでデバイスから直接書き込む場合はboto3を使います:
import boto3
import json
import time
s3 = boto3.client(
's3',
endpoint_url='https://s3.hstorage.io',
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY'
)
def upload_sensor_data(site, sensor_type, device_id, payload):
now = int(time.time())
from datetime import datetime, timezone
dt = datetime.fromtimestamp(now, tz=timezone.utc)
key = f"iot/{site}/{sensor_type}/{dt.year}/{dt.month:02d}/{dt.day:02d}/{device_id}/{now}.json"
s3.put_object(
Bucket='your-bucket',
Key=key,
Body=json.dumps(payload),
ContentType='application/json'
)
データライフサイクル管理:ストレージコストを抑える
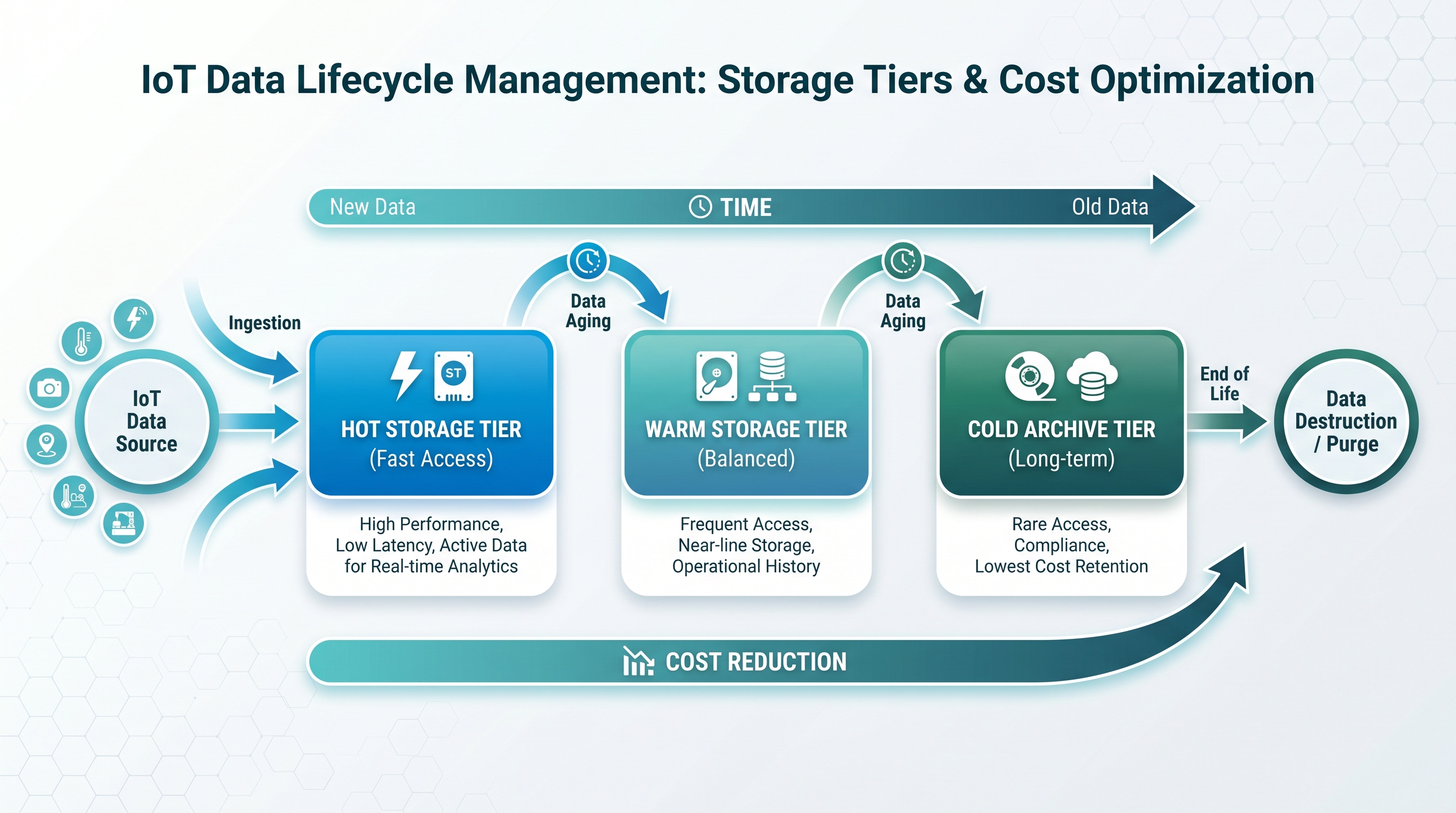
IoTデータのアクセス頻度は時間とともに下がります。この特性に合わせてストレージを使い分けると、コストを大幅に削減できます。
ホットデータ(直近30日):リアルタイムダッシュボードや異常検知で頻繁に参照します。標準のオブジェクトストレージに保存し、レイテンシを低く保ちます。
ウォームデータ(31〜365日):月次レポートや分析で参照します。アクセス頻度は低いため、より安価なストレージクラスへ移行します。
コールドデータ(1年以上):監査対応やコンプライアンスで保持するデータです。アーカイブストレージに移行し、取り出しに数分〜数時間かかっても問題ない運用にします。
AWS S3ではLifecycle Policyで自動移行を設定できます:
{
"Rules": [
{
"ID": "iot-data-lifecycle",
"Filter": {"Prefix": "iot/"},
"Status": "Enabled",
"Transitions": [
{"Days": 30, "StorageClass": "STANDARD_IA"},
{"Days": 365, "StorageClass": "GLACIER"}
]
}
]
}
S3互換ストレージを使う場合、対応するライフサイクル機能の有無を確認してください。
アクセス制御:デバイス単位で権限を分ける
複数の拠点や顧客データを同一バケットに保存する場合、権限設計を誤ると別の拠点のデータが丸見えになります。デバイス単位・パス単位で権限を絞ることが前提です。
読み取り専用APIキー:分析チームやBIツールへのアクセスは読み取り専用で発行します。データを誤って上書きするリスクがなくなります。
パスプレフィックス制限:デバイスAのAPIキーはデバイスAのパスにのみ書き込めるよう制限します。あるデバイスが不正アクセスされても、他のデバイスのデータには触れません。
書き込み専用エンドポイント:フィールドデバイスへのAPIキーは書き込み専用にします。デバイスが盗難・紛失しても、過去のデータを読み取られません。
HStorageでIoTデータを管理する
HStorageはS3互換APIを提供しており、AWS SDKやboto3をそのまま使ってデータを書き込めます。エンドポイントURLとアクセスキーをHStorageのものに変えるだけで、既存のIoTパイプラインをそのまま接続できます。
グループ機能を使うと、拠点別・顧客別にファイルをまとめて管理できます。工場A向けのデータと工場B向けのデータを別グループに分け、グループ単位でアクセス権を設定する構成が実現します。
WebDAVやFTPでの接続もサポートしており、レガシーシステムからのファイル転送にも対応します。センサーデータの可視化やレポートにはS3互換APIを使い、既存の業務システムからのアクセスにはWebDAVを使う、という使い分けも可能です。
HStorageのS3互換APIエンドポイント設定例:
s3 = boto3.client(
's3',
endpoint_url='https://s3.hstorage.io',
aws_access_key_id='your-access-key-id',
aws_secret_access_key='your-secret-access-key',
region_name='auto'
)
既存のAWS S3連携コードから変更するのはendpoint_urlと認証情報の2箇所だけです。
最後に
IoTデバイスのデータ管理は、保存先を決めるだけでは終わりません。パス設計を後から変えるのは大変です。ライフサイクルポリシーを後付けすることはできますが、初期設計のパス構造が悪ければ移行コストが膨らみます。アクセス制御も最初から組み込まないと、後でデバイスごとにキーを発行し直す手間が生まれます。
S3互換ストレージは、デバイスが増えてもストレージ側の設定変更なく追従します。コストはデータ量に比例するため、予算計画も立てやすい。最初の設計を正しく行えば、数年後も同じ構成で動き続けます。
HStorageでのS3互換API利用はドキュメントから確認できます。無料プランから始められるので、まず小規模な構成で動作確認してみてください。