「99.9%の稼働率保証」という文字を見て、どう判断しますか。年間で約8時間45分の停止が許容範囲に入っているかどうかが問われています。基幹業務にクラウドストレージを使うなら、この数字の意味を正確に把握した上でサービスを選ぶ必要があります。
SLAとは何か
SLA(Service Level Agreement)は、サービス提供者と利用者の間で取り決めるサービス品質の契約です。クラウドストレージのSLAで最も目に触れるのが稼働率(可用性)の数値です。月間または年間のうち、サービスが正常に利用できる時間の割合を示します。
ただし注意が必要なのは、SLAは「最低保証」であって「実際の稼働率」ではない点です。多くのサービスは実態として保証値を上回る稼働率を維持していますが、SLAを下回った場合の補償(クレジット)が発生する境界線として機能します。
稼働率の数字が意味する停止時間
「99.9%と99.99%の差は0.09%ポイントだから大したことない」と思う人がいますが、実際の停止時間に換算するとギャップが浮かびます。
| 稼働率 | 年間の許容停止時間 | 月間の許容停止時間 |
|---|---|---|
| 99% | 約87時間36分 | 約7時間18分 |
| 99.9% | 約8時間45分 | 約43分 |
| 99.99% | 約52分 | 約4分 |
| 99.999% | 約5分 | 約26秒 |
月次集計でSLAを設定しているサービスが多いため、月間換算で考えると直感的です。99.9%では月に43分の停止が許容範囲内で、それを超えた分にクレジットが発生します。業務時間帯(平日9時〜18時)に停止が集中すれば、実際の業務影響はさらに大きくなります。

耐久性と可用性は別の指標
SLAの文脈でよく混同されるのが耐久性(Durability)と可用性(Availability)です。
耐久性は「保存したデータが消えないか」を表します。AWS S3やAzure Blob Storage、Google Cloud Storageはいずれも「イレブンナイン(99.999999999%)」の耐久性を謳っています。10億ファイルを保存しても、1年間で1ファイルも失われない水準です。
可用性は「データに今アクセスできるか」を表します。データが消えていなくても、サービスが停止していればアクセスできません。耐久性が高くても可用性は別の話です。
| 指標 | 内容 | AWS S3(Standard) |
|---|---|---|
| 耐久性 | データが消えない確率 | 99.999999999%(11ナイン) |
| 可用性 SLA | アクセスできる時間の割合 | 99.9%(月次) |
イレブンナインの耐久性を誇るサービスでも、可用性SLAは99.9%〜99.99%の範囲が一般的です。ストレージ障害でデータが消えることはほぼないが、障害中はアクセスできない——これが実態です。
主要クラウドストレージのSLA比較
大手3社のSLAを整理します(2026年時点)。
| サービス | 可用性SLA | 耐久性 | 備考 |
|---|---|---|---|
| AWS S3(Standard) | 99.9%(月次) | 99.999999999% | マルチリージョン構成で実質的な可用性は99.99%に近い |
| Azure Blob(Hot/LRS) | 99.9%(月次) | 99.999999999% | RA-GRS構成で読み取り可用性は99.99% |
| Google Cloud Storage(リージョナル) | 99.9%(月次) | 99.999999999% | マルチリージョン構成では99.95% SLA |
| Google Cloud Storage(マルチリージョン) | 99.95%(月次) | 99.999999999% | 複数地域にまたがる冗長化 |
SLAの数値だけで選ぶと判断を誤ります。SLAが同じ99.9%でも、内部の冗長化方式の違いが実際の稼働率に影響します。
冗長化の3方式:LRS・ZRS・GRS
Azure Blob Storageが採用する冗長化の呼び方が整理されていてわかりやすいため、これを例に解説します。
LRS(Locally Redundant Storage):同一データセンター内に3つのコピーを保持します。ディスク故障やラック障害には対応しますが、データセンター全体が停止した場合はアクセスできません。コストが最も低い構成です。
ZRS(Zone Redundant Storage):同一リージョン内の複数の可用性ゾーン(物理的に離れたデータセンター)にコピーを分散します。ゾーン単位の障害が発生してもデータにアクセスできます。LRSより高可用性で、月次SLAも高い数値が設定されています。
GRS(Geo Redundant Storage):異なるリージョン(地理的に数百km以上離れた場所)に非同期でレプリケーションします。リージョン全体の障害や大規模災害に備えた構成です。RA-GRS(Read-Access Geo Redundant Storage)では、障害時に読み取りを別リージョンから行えます。
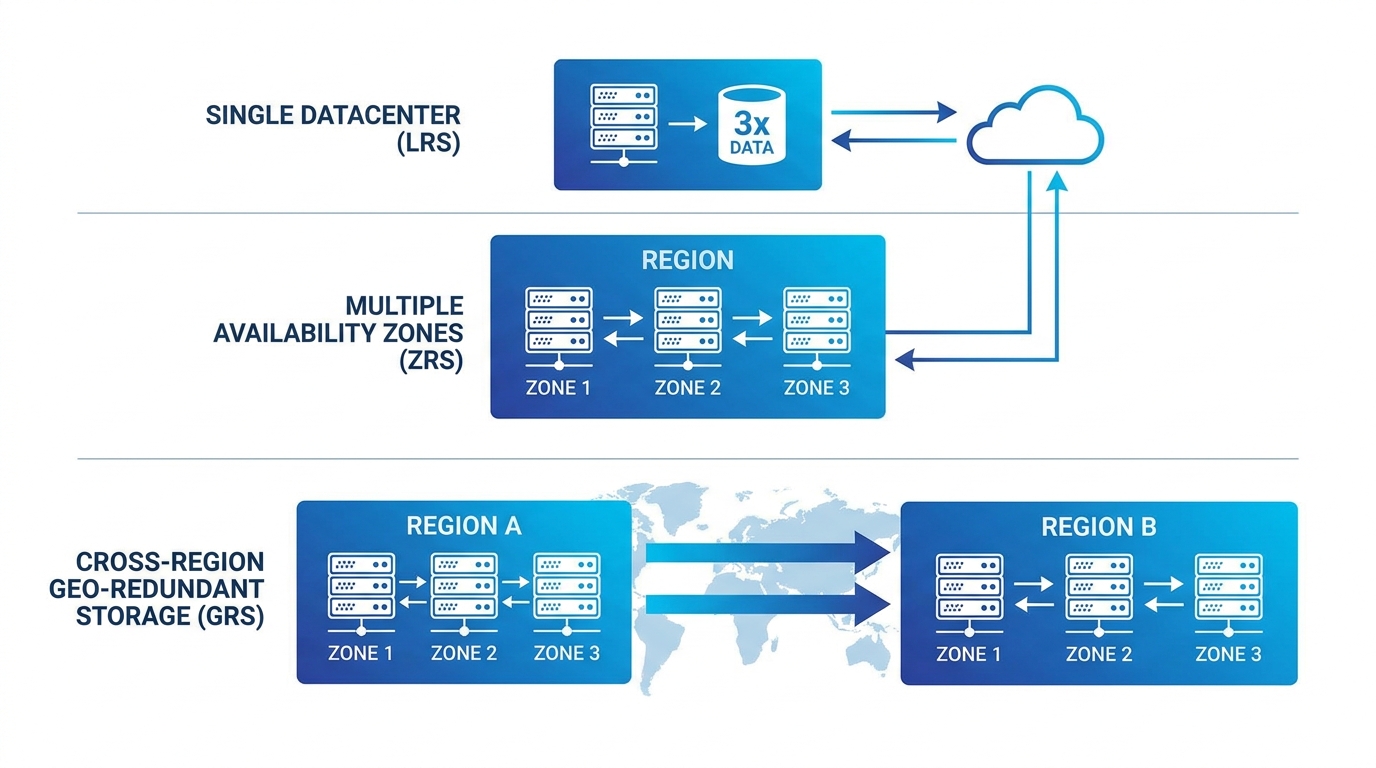
ゾーン冗長 vs リージョン冗長:何を選ぶか
どの冗長化方式を選ぶかは、想定する障害のレベルと許容できるコストで決まります。
| 構成 | 対応できる障害 | コスト | 用途 |
|---|---|---|---|
| LRS | ディスク・サーバー障害 | 低 | 開発環境・一時ファイル |
| ZRS | データセンター障害 | 中 | 業務ファイル・中規模サービス |
| GRS | リージョン規模の障害 | 高 | 重要データのBCP対策 |
業務利用であればZRS以上を選ぶのが現実的です。東日本大震災クラスの広域災害を想定するならGRS(または複数リージョンへの手動レプリケーション)が必要になります。ただし、レプリケーションが非同期のため、障害発生時点で数秒〜数分のデータが失われる可能性(RPO: Recovery Point Objective)があります。
SLA違反時の補償(クレジット)を確認する
SLAを下回った際の補償内容は、各サービスで異なります。AWS、Azure、Google Cloudはいずれも利用料金に対するクレジット(返金)で補償します。補償率はSLAを下回った程度によって変わり、大幅な停止には高い補償率が適用されます。
補償を受けるには自分でクレジットを申請する必要があるサービスが多い。申請しなければ補償は一切受けられません。
補償を受けるには自分でクレジット申請が必要なため、停止が発生したらステータスページで障害を確認し、申請期限(多くは30日以内)を逃さないようにしてください。
SLAには「計画メンテナンスによる停止は計算対象外」という条件が付くことがあります。契約前に除外条件を読んでおきましょう。
RPOとRTOを定義する
BCP(事業継続計画)の観点では、SLAの稼働率だけでなくRPOとRTOの定義が重要です。
RPO(Recovery Point Objective):障害発生時に「どこまでのデータ損失を許容できるか」を示します。非同期レプリケーション構成では、レプリケーション遅延分(数秒〜数分)のデータが失われる可能性があります。ゼロRPOが必要な場合は同期レプリケーションが必要です。
RTO(Recovery Time Objective):「どれだけ早くサービスを再開できるか」を示します。GRS構成でも、フェイルオーバーの実行には数時間かかるケースがあります。自動フェイルオーバーをサポートするかどうかも確認ポイントです。
HStorageの可用性設計
HStorageはWasabiのオブジェクトストレージをバックエンドに使用しており、Wasabiが保証する99.9%の可用性と99.999999999%(イレブンナイン)の耐久性がベースになっています。データはWasabiのデータセンターで複数のコピーが保持され、単一のディスクや機器の障害でファイルが失われる構造ではありません。
HStorageのAPIサービス層(api.hstorage.io)についても冗長化された構成で運用しており、障害情報はステータスページでリアルタイムに確認できます。
重要なファイルについては、HStorage内でのバージョン管理機能を活用することで、誤削除や意図しない上書きからの復旧が可能です。さらにリスクを下げるなら、別のクラウドストレージにコピーを持つ3-2-1バックアップ構成を組み合わせることをお勧めします。
まとめ
クラウドストレージのSLAを読む際に確認すべき点を整理します。
- 稼働率の数値だけでなく、月次か年次かを確認する
- 耐久性(データが消えないか)と可用性(今アクセスできるか)は別の指標
- 冗長化方式(LRS/ZRS/GRS)によって実際の可用性が大きく変わる
- 計画停止の扱いと補償申請の手続きを事前に確認する
- RPO/RTOを定義し、必要な冗長化レベルを逆算して選ぶ
「99.9%あれば十分」と判断する前に、月43分の停止が業務に与えるコストを試算してください。冗長化の追加コストとそのコストを比較すれば、ZRSやGRS構成への投資が割に合うかどうかが明確になります。